
Before diving into the details of my custom Gherkin interpreter, a fundamental understanding of e2e testing and the Gherkin convention is essential. Additionally, familiarity with basic TypeScript concepts will be required.
Why I Crafted My Own Gherkin Interpreter for E2E Tests
As I've aged, I've found myself forgetting details, especially when dealing with new information that isn't part of my daily routine. Existing Gherkin interpreters have limitations; they lack the intelligence to remember titles for specific testing steps and provide insufficient hints. This deficiency persists regardless of the Integrated Development Environment (IDE) choice.
Therefore, I decided to create my own Gherkin interpreter using plain TypeScript.
Why Not Cucumber or Alternatives?
The straightforward answer is the absence of hints during test development and the verification of sample data against my tests. For instance, a test step titled "I see user with name 'piotr1994'", when expecting a username as a string, might fail during runtime. To avoid such situations, I aimed to enhance autocomplete mechanisms, introduce type safety, and catch errors at compile time. Given that e2e tests can be time-consuming, identifying problems early significantly saves time.
To understand it, see the following Cucumber syntax as plain text:
Feature: User Login
Scenario: Successful Login
Given the user navigates to the login page
When the user enters valid credentials (username and password)
And clicks on the login button
Then the user should be redirected to the dashboard
Scenario: Invalid Login
Given the user navigates to the login page
When the user enters invalid credentials
And clicks on the login button
Then an error message should be displayed
And the user should stay on the login page
The next problem that I've spotted that distracts me a lot is jumping between files a lot. Generally, I love Separation of Concerns, but sometimes it makes me mad when it hurts productivity.
Cucumber Feature File (File 1) JavaScript Test File (File 2)
+-----------------------------+ +----------------------------+
| Feature: User Login | | describe('User Login', () |
| | | => { |
| Scenario: Successful Login | | |
| Given the user... | | it('should perform... |
| When the user... | | // Test implementation|
| Then the user... | | }); |
| | | |
| Scenario: Invalid Login | | describe('Invalid Login',|
| Given the user... | | () => { |
| When the user... | | |
| Then an error... | | it('should display... |
+-----------------------------+ | // Test implementation|
| }); |
+----------------------------+
^ ^
| |
Cursor points to "When..." Cursor jumps to "Invalid Login"
The jump will work only if you've installed an extension or you have a really smart IDE. For Visual Studio Code, it doesn't work by default...
The last problem, the most important one is the option to provide a typo and waste a lot of time waiting for results in the executed e2e environment. You may laugh right now, but seriously, it may take a lot of your important time daily, and if you summarize it - it's an hour or two hours during a week...
The Project Requirements
In the project that we've worked on, our team is using TDD and BDD often to craft requirements in tickets. Next, developers pick these requirements, do a job, and testers create an e2e scenario in Cucumber to check if it is working or not. At this point is a huge duplication of work - we're doing things twice. Instead of having already prepared scenarios based on available scenarios in Cucumber, we need later to map the requirements from the ticket to scenarios and check if it makes sense.
It happens because you're not able to remember all scenarios during refinement - lack of autocomplete...
The API Design
We've decided to use the Chain Of Responsibility pattern to write our tests like that:
// Reusable commands
const BASE_COMMANDS = {
'I sign in': () => {
// Using already defined commands.
BASE_COMMANDS[`I click button`]([`Clear content`, `Sign in`]);
},
'I click button': (titles: ClickableControls[]) => {
// Command logic.
titles.forEach((title) => {
cy.get(`button[title="${title}"]`).click();
});
},
}
// Passing commands.
const { Given } = Gherkin(BASE_COMMANDS);
Now in tests:
it(`user may log in and log out`, () => {
Given(`I see disabled button`, [`Sign in`])
.When(`I move mouse`)
.Then(`I see not disabled button`, [`Sign in`])
.When(`I click button`, [`Sign in`])
.Then(`I not see button`, [`Sign in`])
.When(`I click button`, [`User details and options`])
.Then(`I see text`, [`Your Account`])
.And(`I see button`, [`Sign out`]);
});
Demo
See the following GIF to understand the benefits and autocomplete mechanism that we gain with our tool:
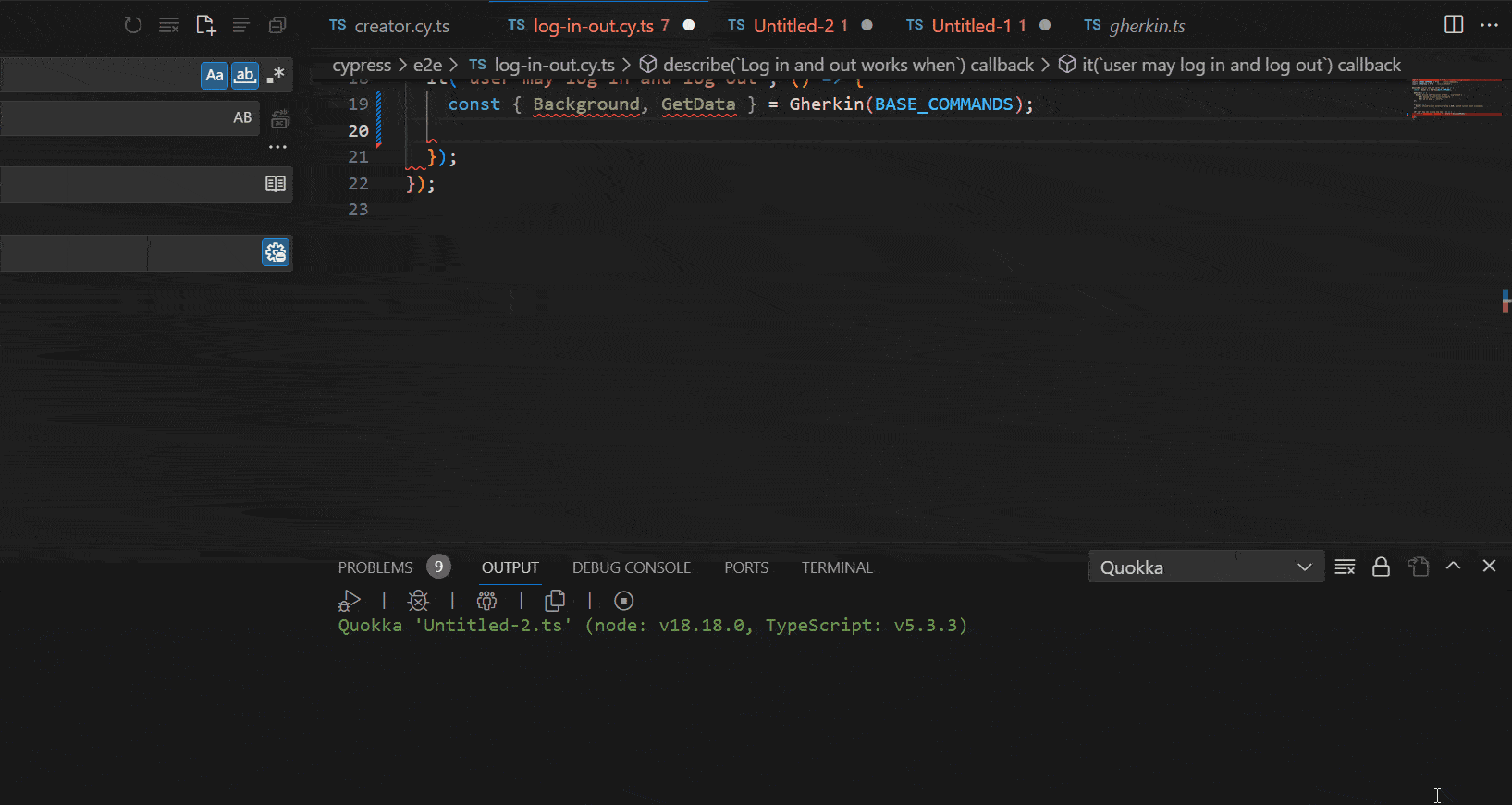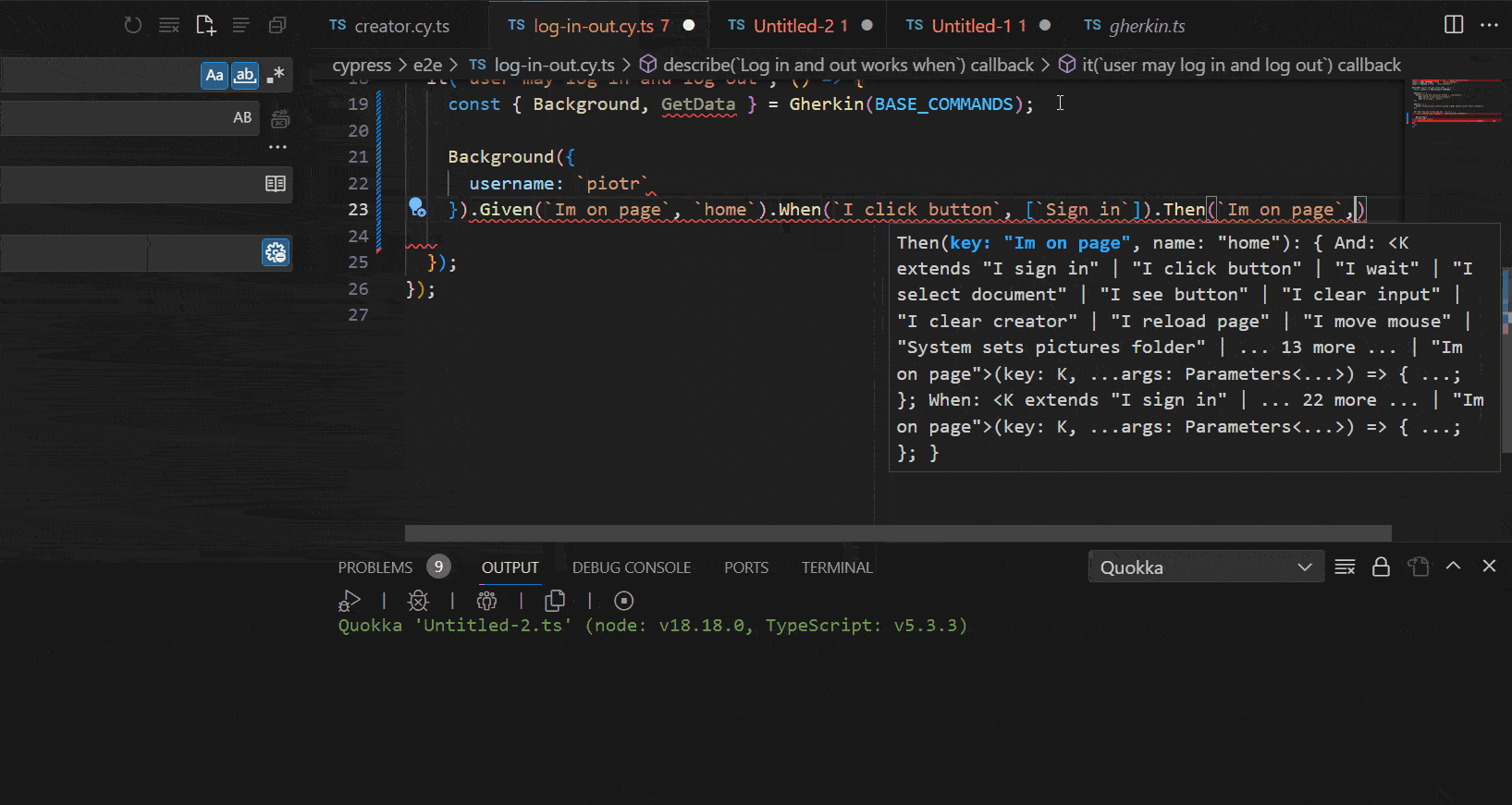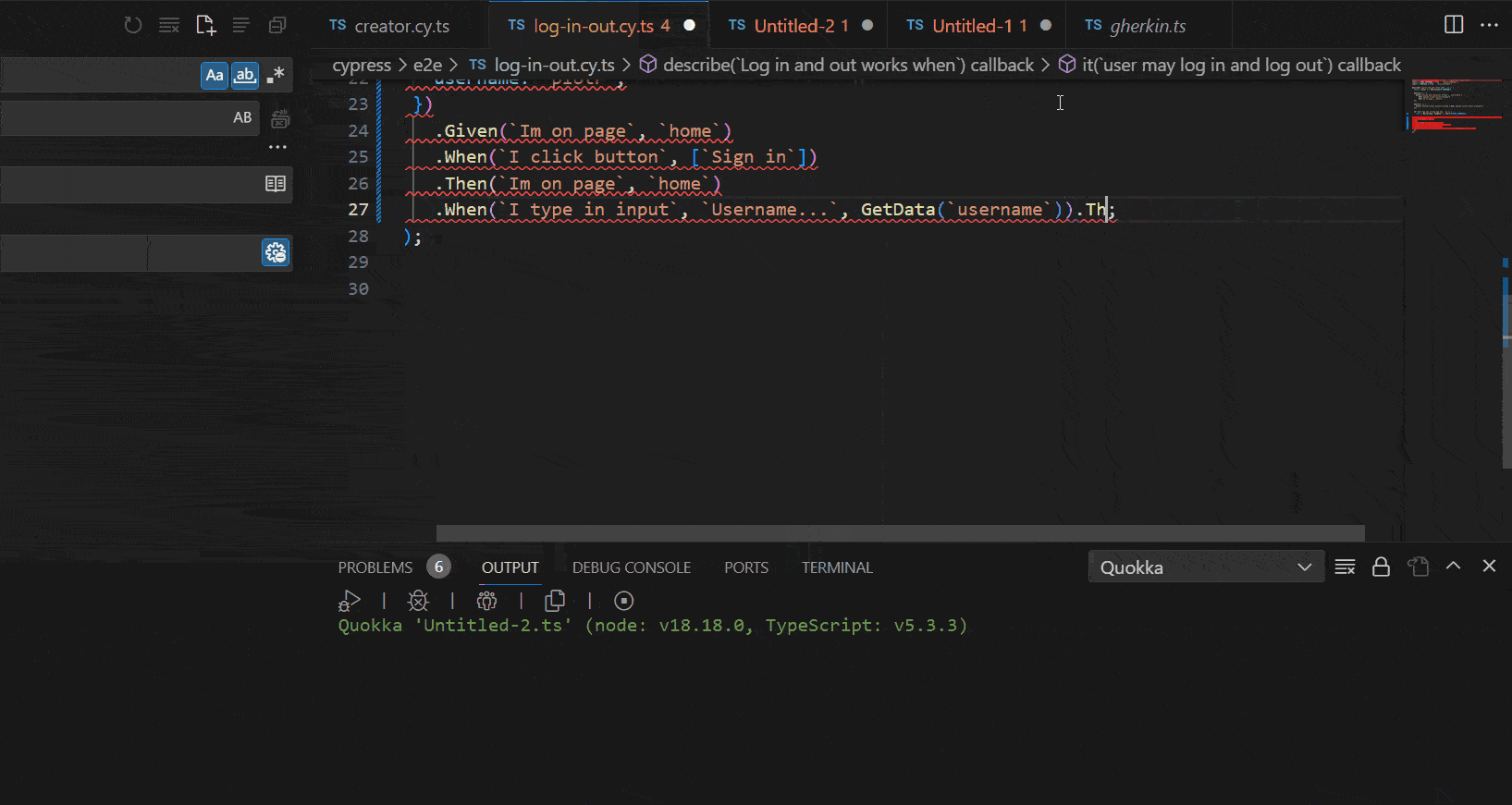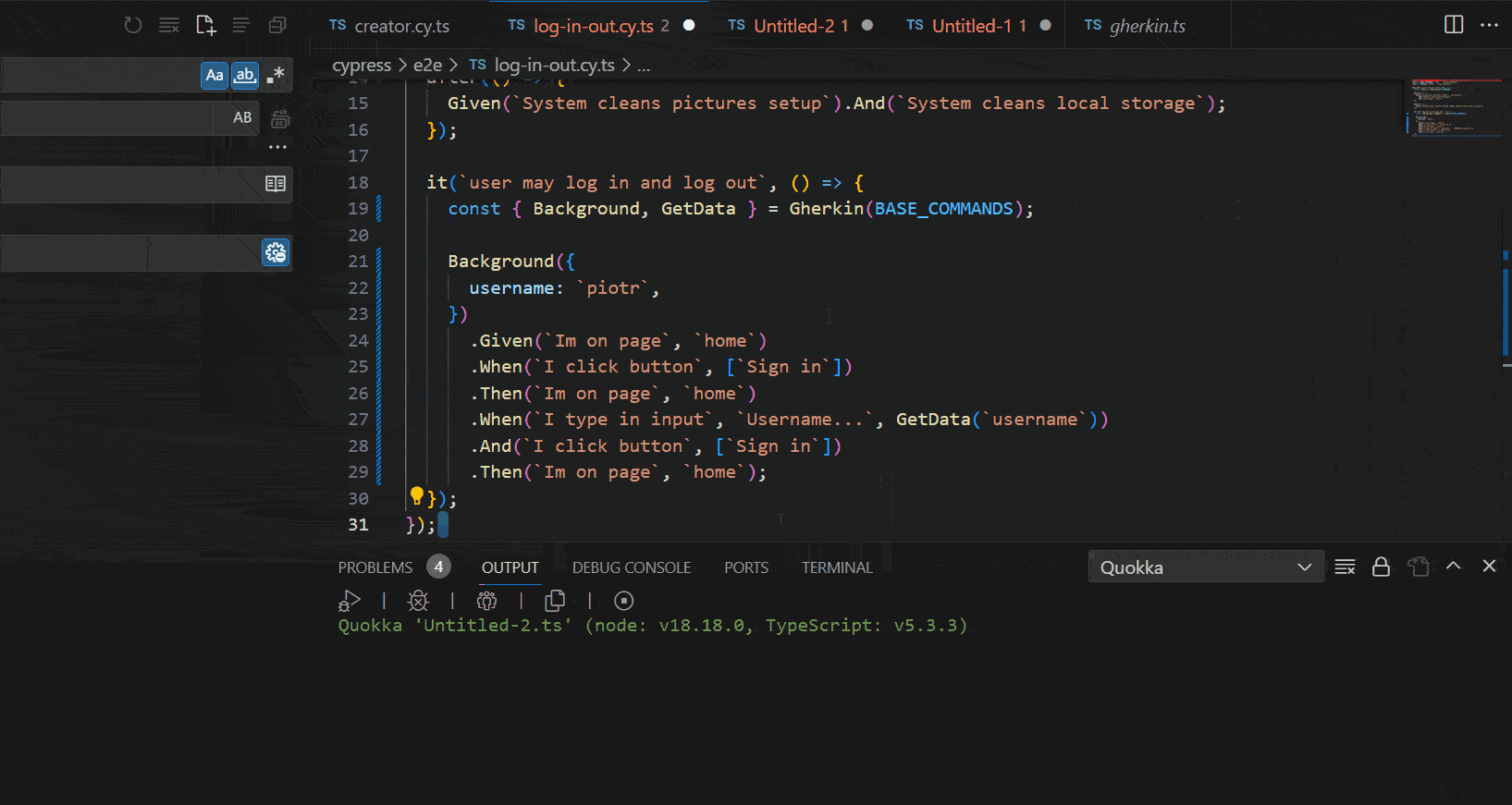 Showcase
Showcase
Implementation
type Commands = Record<string, (...args: any[]) => void>;
type Data = Record<string, any>;
function Gherkin<C extends Commands, D extends Data>(commands: C) {
let data: D;
// You can accumulate data during tests and use it later.
function GetData<K extends keyof D>(key: K) {
return data[key];
}
// You can accumulate data during tests and use it later.
function GetBackground() {
return data;
}
// You can accumulate data during tests and use it later.
function Background(newData: D) {
data = { ...data, ...newData };
return {
Given,
};
}
// Parameters infer arguments from the given function
// under commands object.
function Given<K extends keyof C>(key: K, ...args: Parameters<C[K]>) {
cy.log(key as string); // Logs data in test execution.
commands[key](...args);
// We return an object without the Given function because
// it's already used and doing Given.Given is not aligned with Gherkin
// convention.
return {
Then,
When,
And,
};
}
function Then<K extends keyof C>(key: K, ...args: Parameters<C[K]>) {
cy.log(key as string);
commands[key](...args);
return {
And,
When,
};
}
function When<K extends keyof C>(key: K, ...args: Parameters<C[K]>) {
cy.log(key as string);
commands[key](...args);
return {
And,
Then,
};
}
function And<K extends keyof C>(key: K, ...args: Parameters<C[K]>) {
cy.log(key as string);
commands[key](...args);
return {
Then,
When,
And,
};
}
return { Given, When, GetData, Background, GetBackground };
}
export { Gherkin };
To make it simpler, we've used the hoisting mechanism to not care about function declaration order. With function expression syntax - const fn = () => {}, we'll need to care about order. So that's why we've picked declarations.
Next, the Parameters utility type infers the arguments from the given command object and remembers their type. This gives a huge boost of time-saving - you may declare titles or other arguments in a single place, and then you'll gain type-safety + hints during the development of tests.
In addition, take a look at returned objects in each function - we are limiting the possibility to use stuff like that: Given.Given.Given or When.When.When, because it does not match the convention.
The last part is the option to provide additional mechanisms - we've added a function that allows us to accumulate data during tests and use it later for expected statements. For example, imagine a situation when you want to pick an input value typed by a user, instead of hard coding it inside variables. It may be useful when testing translation stuff or data provided by the user.
it(`user may log in and log out`, () => {
const { Background, GetData } = Gherkin(BASE_COMMANDS);
// Data is assigned here.
Background({
username: `piotr1994`,
})
// Reading the data from any source.
.Given(`I see button`, GetData('username'))
.Then(`I click button`, [`Change document name`]);
});
Pros
- Faster tests crafting
- Hints during test creation
- Compile time type-safety
- Option to limit test scenarios and compose them
- Nice and easy to use/understand API
- Parameters autocomplete
- No external dependencies
- You can customize
- Migration to other testing frameworks is much easier
Cons
- Additional code to maintenance
- Need to craft own documentation for this code
- The used TS code may be hard to follow for TS newcomers
The Result
Okay, so we have the following tool, and now how do we embed it in our team ticket refinement process? Before every sprint, we pick tickets to work on, but right now, we're crafting automatically e2e tests in the refinement process and just copying them into the codebase. When the developer finishes his work, he just tries to run these tests and figures out why it doesn't work. If it works, it usually means the work is done, and we've automatically covered features.
Of course, I'm not a liar, and sometimes it was a little bit problematic - for example, the prepared test scenarios were invalid, but still, the time used to fix scenarios was much smaller due to hints, autocomplete, and compile-time checking with TypeScript.
In addition, it takes some time to master and align a process to this tool a little bit, but the benefits that we gain - mostly time, and TDD out of the box, give us much more time to do other important aspects in our codebase.
Source Code
Under following Github repo you may see how we craft our e2e tests with this simple tool: https://github.com/polubis/4markdown/tree/develop/cypress
Summary
As you saw, sometimes inventing the wheel again makes sense. It's not like I recommend you to use the following approach always, but when you have a repetitive problem that makes you mad, it's worth trying to solve it - firstly with available tools. If they do not exist, you need to do something on your own.
It worked for our team and project; you may try it and create your own opinion.
Searching for a mentor in any web technology like React, Cypress, Node, AWS, or anything else? Maybe you have a single problem and just want to solve it quickly so you can continue with more important work? Good news! We are a company focused on mentoring, education, and consultation aspects. In addition, we craft apps, educational materials, and tons of articles. If you're interested, here are some useful links to contact us and access our educational materials 🌋🤝
Bullshit Meter
Looks solid
Bullshit score
0.0/10
Comments (0)
No comments yet
Be the first to comment on this document.